Personal & Contact Information
First name · Last name · Full name · Email address · Phone number · Address · City · State · Country · Zip / Postal code · LinkedIn URL · Skype ID · Other contact information
uRecruits is an AI resume parser that processes every uploaded resume the moment it enters the platform, extracting 30+ structured data points across identity, contact, skills, experience, education, and certifications. Every field lands on the candidate record automatically, ready for matching, scoring, and reporting. No manual data entry. No copy-paste.
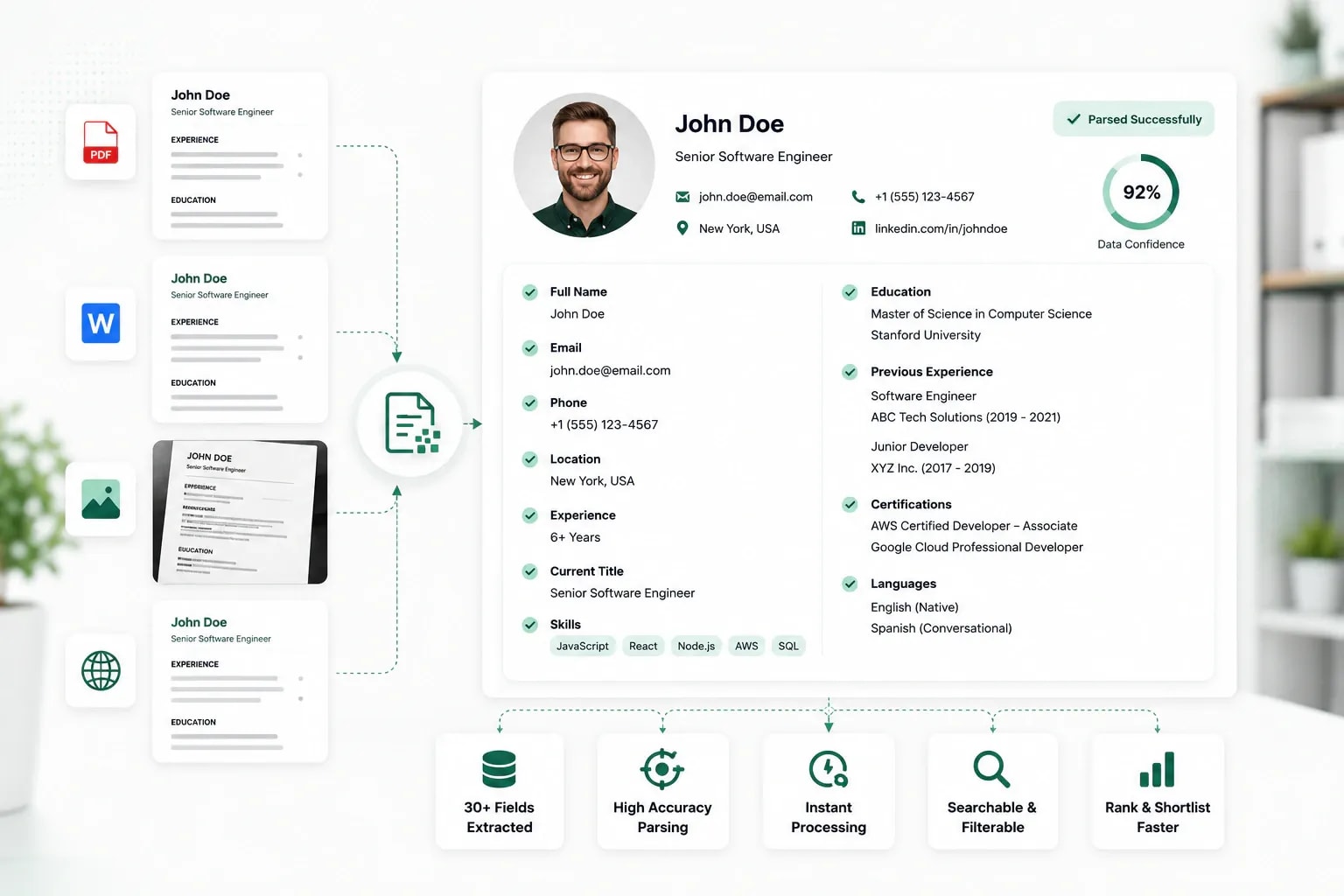
A candidate applies and the AI resume parsing software processes their resume automatically. No upload step for the recruiter. No waiting. Within seconds, 30+ structured fields populate the candidate record, ready for matching, search, filtering, and scoring. This automated CV parser handles every format recruiters actually receive: standard PDFs, legacy Word files, plain text, and modern DOCX. Every parsed field is editable on the candidate record. If parsing missed something, the recruiter corrects it in seconds and the edit is logged with actor and timestamp.
Every resume is formatted differently. Some are two pages, some are one. Some have tables or columns, some have none. Manual resume screening means reading every one of them and re-entering the same data into your system. Resume parsing fixes that, turning every document into structured, searchable, comparable candidate data automatically.

Resume parsing turns a formatted document into a structured candidate record with 30+ data points across 6 categories, all searchable, filterable, and ready for every downstream capability.
First name · Last name · Full name · Email address · Phone number · Address · City · State · Country · Zip / Postal code · LinkedIn URL · Skype ID · Other contact information
Headline / current title · Professional summary or objective · Current position · Current company · Industry · Years of total experience · Work type (remote / hybrid / onsite) · Notice period · Category · Sub-category
Company name · Current company · Current position · Employment dates (start and end) · Employment type (full-time / contract / internship) · Industry · Work type · Years of experience · Projects
Current salary · Salary currency · Salary frequency · Expected salary · Expected salary currency · Expected salary frequency · Notice period · Availability status
Diploma / degree · Institution / university name · Field of study · Graduation date · Graduation year · GPA (if listed) · Academic honors and awards
Technical skills · Soft skills · Tools and software · Tags / keywords · Proficiency levels (where indicated)
Certification name · Issuing organization · Issue date · Expiration date · Credential ID
Language name · Language proficiency level (native / fluent / professional / conversational)
Reference name · Reference contact · Professional references
Professional summary · Publications · Patents · Volunteer experience · Projects · Description / notes · References (if listed)
Candidates submit resumes in every format, template, and layout. uRecruits AI resume parsing handles the full range, not just clean standard PDFs.
The semantic AI resume parser handles multi-column layouts, creative-industry designs, and non-standard section headers far better than traditional rule-based parsers. Any field that cannot be extracted confidently is flagged for recruiter review, not silently wrong.
Supports PDF, DOC, DOCX, and TXT. Text-extractable PDFs and DOCX files achieve the highest accuracy. Image-based PDFs use built-in OCR. Legacy DOC and plain TXT files are supported for older resume templates.
A candidate using a graphic designer template with multi-column, icon-heavy layout is handled the same way as a plain Word document. The parser normalizes structure regardless of visual design.
Processing hundreds of applications per role means hundreds of resumes to read and manually enter. Our resume parsing software extracts all 30+ fields on every application, so recruiters start reviewing structured data rather than raw documents.
Parsed candidate data stays on the candidate record indefinitely. When a new role opens, Talent CRM surfaces previously parsed candidates whose skills, experience, and location match the new role, without re-entering any data.
Multi-language resumes, international education systems, and non-standard credential formats are handled through the parsing engine. Highest accuracy on English-language resumes. Multi-language support depends on deployment configuration.
Resume Parsing handles scanned images and image-based PDFs using built-in OCR. Text is extracted automatically, then parsed like any other resume.
Yes. The default 30+ fields cover the vast majority of hiring use cases, but the field schema can be extended or customized through API configuration.
The AI resume parsing engine handles edge cases including multi-column layouts, creative designs, and non-English resumes far better than traditional rule-based parsers. Any field that cannot be confidently extracted is flagged so recruiters can review. Accuracy is highest on well-formatted English-language PDFs and DOCX files.
Yes. All parsed data is stored in encrypted databases. The platform uses role-based access controls and complete audit trails. Every parsed field and manual edit is logged with actor and timestamp.
30+ structured fields per resume, across six categories: Identity, Contact, Skills, Experience, Education, and Certifications. Every field is available on the candidate record for search, filter, matching, and reporting.
PDF, DOC, DOCX, and TXT. Standard PDF and DOCX files have the highest parsing accuracy. Image-based PDFs require OCR. Confirm additional format support with your account team during onboarding.
Yes. Every parsed field on the candidate record is editable. Edits are logged with actor and timestamp. If you upload a new version of the resume, parsed fields refresh automatically and manual edits are preserved unless explicitly overwritten.
One candidate record. One parsed data set. Multiple application contexts. The resume is parsed once and reused across every role the candidate applies to. Parsed skills, experience, and location are available for matching against each new role.
uRecruits uses a first-party AI resume parsing engine, not a third-party vendor. The parser uses structured extraction and AI-assisted extraction depending on file type. It extracts information from the resume and places it into structured fields on the candidate record. uR Agent can then summarize, query, or compare parsed records through natural language commands.
Yes. CSV and PDF exports are available on all packages that include Resume Parsing. Bulk parsing API and parsed-data export API are available on the Full Cycle plan. Parsed data can also be exported to integrated HR systems when a candidate is hired.
Practical guides to help your team get more from your AI resume parsing tool and structured candidate data.

Learn how AI-powered Applicant Tracking Software streamlines recruiting, cuts hiring costs, job posting, resume parsing, and delivers real-time insights for smarter hiring.

Our intelligent screening engine uses a customizable scoring system to instantly prioritize top candidates. Combined with bias-reduction algorithms, it helps you hire based on merit, not background.

Recruiters are moving to AI job marketplaces for faster hiring, smarter matching, and lower costs. Explore the benefits driving this shift in recruitment.
Want to see how accurately Resume Parsing handles the kinds of resumes your team actually receives? Upload a few during your demo, and we'll show you the structured data come back in real time fields, skills, experience, and all.